
 |
|
||||
BiographyJohannes Ender was born in 1988 in Hohenems, Austria. In 2013 he finished his Master’s studies at the University of Applied Sciences in Vorarlberg. After working in industry for three years he pursued the Master’s studies of Computational Science at the University of Vienna. In November 2018 he joined the Institute for Microelectronics where he started his PhD studies researching the simulation of non-volatile magnetic memory devices. |
|||||
Increasing Switching Reliability in SOT-MRAM Cells Using Reinforcement Learning
Spin-orbit torque magnetoresistive random access memory (SOT-MRAM) is non-volatile, fast, and exhibits considerable endurance. These properties make SOT-MRAM suitable for replacing existing charge-based RAM in registers or high-level caches. In perpendicularly magnetized SOT-MRAM cells, however, an external magnetic field is needed to deterministically reverse the magnetization.
A recently proposed SOT-MRAM cell architecture enables field-free, purely electrical switching by applying current pulses to two orthogonal heavy metal wires attached to the top and bottom of the ferromagnetic free layer of the memory cell. Current flowing through these metal wires creates spin-orbit torque acting on the magnetization. The choice of current amplitude, as well as the temporal delay or overlap of the current pulses, opens up a huge space of possibilities to optimize switching, and finding efficient pulse sequences remains a challenging problem. Reinforcement learning (RL), a sub-branch of machine learning, has proven suitable for such complex problems. By repeated interaction with an environment, an agent gathers experience in the form of a reward signal corresponding to a certain optimization objective and tries to maximize the accumulated reward by continuously refining its strategy of applying actions.
We trained an RL agent to interact with an environment consisting of a finite difference simulation of the previously described SOT-MRAM cell. The successfully trained agent can subsequently be used to optimally turn pulses on and off during simulation time for fast switching of the cell. Fig. 1 shows the accumulated reward of the agent for variations of the saturation magnetization and the anisotropy constant by up to 10%, corresponding to the variability that can be observed in MRAM fabrication processes. A higher accumulated reward corresponds to the z-component of the magnetization being brought closer to the target value, i.e., reversal of the magnetization. The agent can successfully reverse the magnetization in 42% of the simulations. These results were subsequently used to extract a static pulse sequence, which can be seen in Fig. 2, consisting of a single NM1 pulse and two NM2 pulses. Performing further simulations with varying material parameters, but applying this extracted static pulse sequence, produced the results presented in Fig. 3. Compared to the results using the trained agent to dynamically set pulses, the amount of successfully switched simulations increased to 55%. Machine-learning-assisted derivation of better switching pulse sequences could drastically improve switching performance of emerging memory devices.

Fig. 1: Accumulated reward achieved by the trained RL agent. Anisotropy constant K and saturation magnetization Ms were varied by +/-10%. Results are shown for a total of 441 realizations.

Fig. 2: Static pulse sequence extracted from successfully switched simulation runs with varying anisotropy constant and saturation.
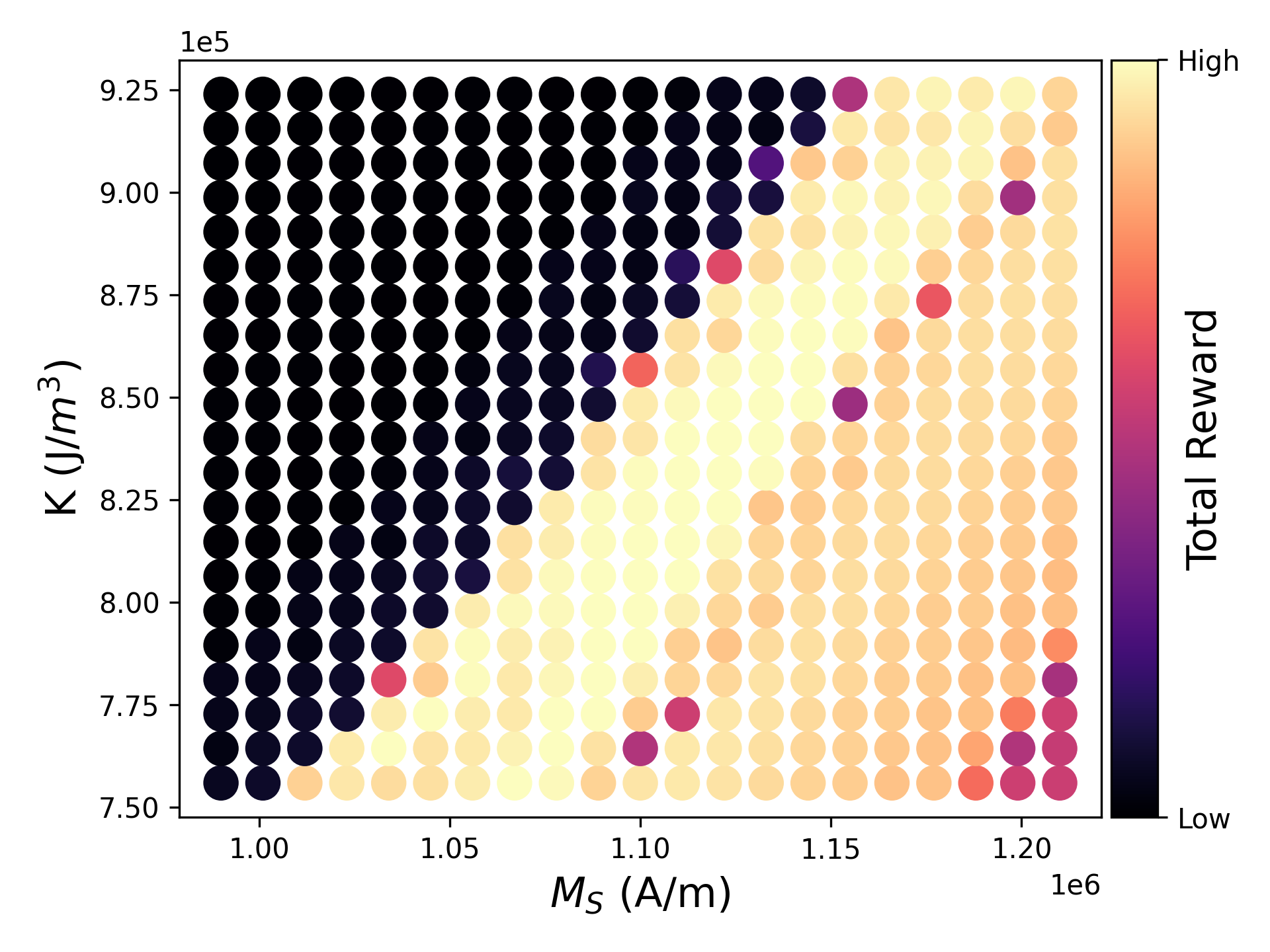
Fig. 3: Accumulated reward achieved using the derived static pulse sequence. Anisotropy constant K and saturation magnetization Ms were varied by +/-10%. Results are shown for a total of 441 realizations.