
 |
|
Biography
Lukas Gnam was born 1991 in Wr. Neustadt, Austria. He received his Bachelor's Degree in Technical Physics and his Master's Degree in Physical Energy and Measurement Engineering from the Technische Universität Wien in 2014 and 2016, respectively. After finishing his studies he joined the Institute of Microelectronics in April 2016, where he is currently working on his doctoral degree. His research focus is on high performance parallel mesh generation algorithms.
A Flexible Coarse-Grained Shared-Memory Parallel Mesh Adaptation Workflow
Unstructured meshes are commonly used within finite element or finite volume methods for the numerical solution of partial differential equations. To reduce the discretization error, the initial mesh is locally or globally adapted. This mesh adaptation is a critical step and often poses an unwanted bottleneck. A lot of work has therefore been conducted to parallelize adaptive meshing methods for distributed-memory systems for large-scale finite element problems. As more and more cores per node become available, however, applications based on numerical simulations on shared-memory machines need to exploit on-node parallelism. We apply a coarse-grained parallelization technique, which enables the use of available serial meshing algorithms with little overhead whilst simultaneously offering considerable parallel efficiency.
Our pipeline starts with partitioning the input mesh into contiguous mesh partitions (submeshes), as indicated in Fig. 1. The second step is the creation of the adjacency information of all submeshes, which are colored in the third and last step of the serial section. After the coloring, we start the mesh refinement process by iterating in parallel over all partitions with color 0 and process these submeshes. Before the refinement of the next color can start, each partition has to check if vertices have already been inserted by the neighboring partition into one of its interfaces. Afterwards, the mesh refinement starts again for each partition with the active color.
We evaluated the performance of our method using 2D and 3D box geometries. As shown in Fig. 1 and Fig. 2, our parallelization method yields speedups of 3.4 to 4.0 times in two dimensions and 4.3 to 4.4 times in three dimensions. These speedups are better than those of the comparison framework PRAgMaTIc, with the exception of the smaller 2D test mesh, whereas, in terms of refinement execution times, our method outperforms PRAgMaTIc in all cases.
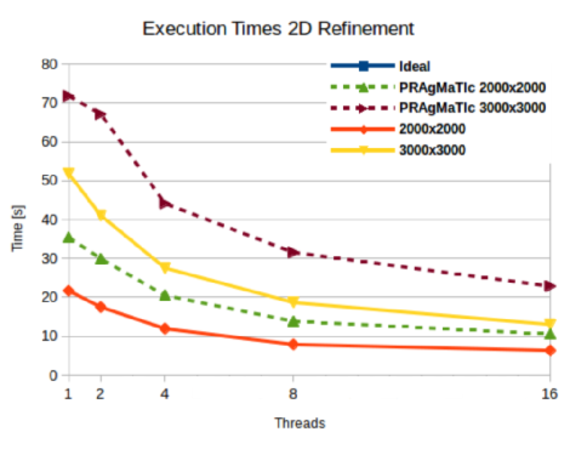
Fig. 1: Execution times of the 2D refinement procedure, where the solid lines represent our method and the dotted lines the results obtained using PRAgMaTIc. Results were obtained with 256 partitions.
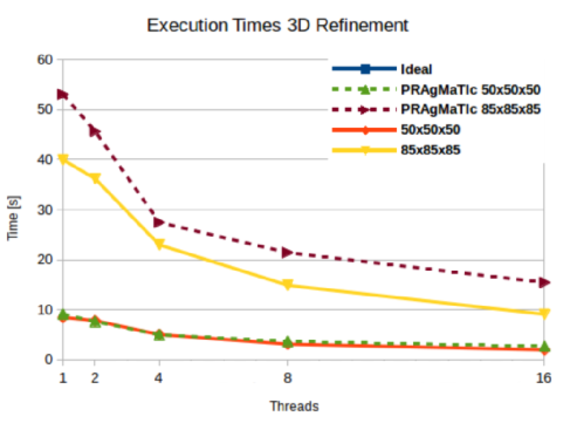
Fig. 2: Execution times of the 3D refinement procedure, where the solid lines represent our method and the dotted lines the results obtained using PRAgMaTIc. Results were obtained with 1,024 partitions.
