
 |
|
Biography
Karl Rupp was born in Austria in 1984. He received the BSc degree in electrical engineering from the Technische Universität Wien in 2006, the MSc in computational mathematics from Brunel University in 2007, and the degree of Diplomingenieur in microelectronics and in technical mathematics from the Technische Universität Wien in 2009. He completed his doctoral degree on deterministic numerical solutions of the Boltzmann transport equation in 2011. His scientific interests include generative programming of discretization schemes such as the finite element method for the use in multiphysics problems.
Parallel Semiconductor Device Simulation
Modern processors consist of billions of transistors with characteristic length scales of only several nanometers. With every new processor generation, the number of transistors increases, perpetuating Moore's Law. However, the sequential performance of modern processors has not increased substantially within the last decade (see Fig. 1). Instead, additional transistors are spent on additional compute cores and longer vector registers. To leverage the full computational performance of such parallel computing architectures, parallel workloads are essential.
Many established semiconductor device simulation approaches, in particular macroscopic models, such as the drift-diffusion model, have been designed for sequential processors. As a consequence, these approaches do not benefit from the increasing number of processor cores but are instead limited by sequential performance. Unfortunately, the sequentially most efficient methods, like the ones in many established semiconductor device simulation approaches, typically show only low parallel efficiency. For example, the popular incomplete LU factorization preconditioners for the iterative solution of the linearized drift-diffusion system in each Newton step are inherently sequential and cannot make use of additional processor cores.
Ongoing research at the Institute for Microelectronics investigates novel simulation approaches, bearing in mind high parallel efficiency. This involves the design of semiconductor device simulations that can be run with thousands of processes, possibly with hundreds of threads each, on supercomputers like the Vienna Scientific Cluster. Sequential bottlenecks, like the conventional incomplete LU factorizations mentioned earlier, are resolved by using fully parallel alternatives instead. When run on a single core, these parallel alternatives cannot compete with the established approaches. When run on tens or hundreds of cores, however, the parallel variants significantly outperform the sequential algorithms.
To maximize the impact of this research, all codes are made available as free open-source software and can be reused by researchers and practitioners all over the world. For example, the linear algebra software library, ViennaCL, developed at the Institute for Microelectronics, is downloaded over 100 times each week. This also supports the idea of reproducible science, allowing anyone to easily verify the research results.
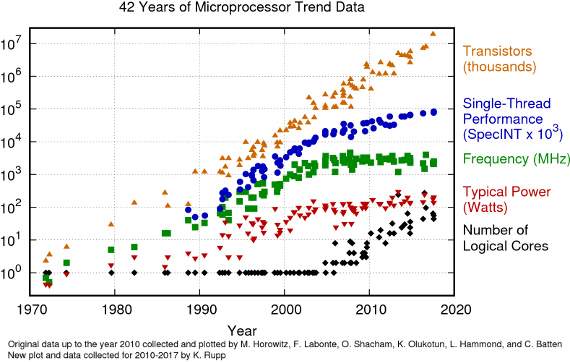
Fig. 1: Microprocessor trend data spanning 42 years. Because of power constraints, clock frequencies have not increased since 2005, limiting sequential performance. Instead, modern processors include additional cores, resulting in the need for parallel workloads.
