
 |
|
||||
BiographyJohann Cervenka was born in Schwarzach, Austria, in 1968. He studied electrical engineering at the Technische Universität Wien, where he received the degree of Diplomingenieur in 1999. He then joined the Institute for Microelectronics at the Technische Universität Wien and received his PhD in 2004. His scientific interests include three-dimensional mesh generation, as well as algorithms and data structures in computational geometry. |
|||||
GPU Utilization for the Schrödinger Equation
In the development of modern and future electronic devices, quantum mechanical effects exhibited in carrier transport must often be accounted for. During the enhancement of device simulators, the Wigner and Schrödinger methods are benchmarked to one another. Common to these problems, huge equation systems must be assembled and solved. To achieve accurate results, the simulation of the transport equation of the quantum mechanical systems and the electrical problem are simulated self-consistently.
Especially in phase-space, this method requires a large number of simulations. In detail, for one operational point the Jacobian with respect to the space vector has to be carried out for each phase value, either representing a separate solution of the Schrödinger equation. This technique has to be connected in an update loop to a Laplace solver.
Fortunately, the solving mechanism shows a variety of similar independent simulations which seem feasible for parallelization and transferable to GPUs. Here several mechanisms of treating the matrices have been examined.
The C++ Eigen library shows that transferring the matrix operations to the GPUs is possible in a convenient and performant way. Preliminary to the matrix operations, the host memory must be transferred to the operable device memory of the GPUs. Afterwards, the independent operations can be computed in parallel on the GPUs. The solutions can then be transferred back to the host to be further utilized.
In the figure, the speedup is carried out. The time-consumption of the solution in dependence to the parallelization is depicted. Typically, 300 phase configurations, with a set of 3000 Schrödinger equations comprising a spatial resolution of 1000 points, must be connected to the feedback loop. Scalability up to several thousands of calculations in parallel can be observed. The simulations were carried out on an NVIDIA T4 tensor core adapter equipped with 2560 CUDA cores and on an NVIDIA GTX 1080 adapter capable of 3500 operations, as well as on Intel i7 processors for reference.
Further research will be conducted embedding the solution of the Laplace equation in the GPU. The possibility of using single precision operations rather than double precision operations will be examined.
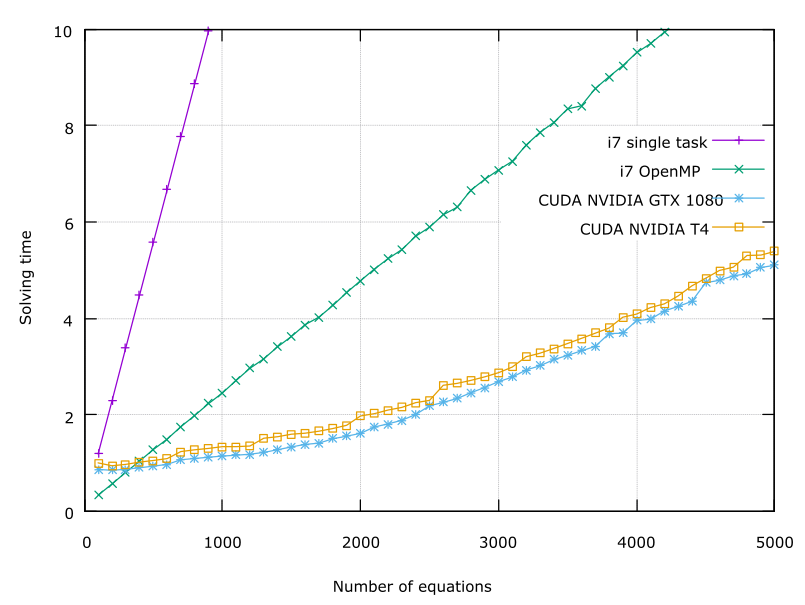
Fig. 1: Comparison of the calculation times for solving Schrödinger equations in parallel.