
 |
|
Biography
Karl Rupp was born in Austria in 1984. He received the BSc degree in electrical engineering from the Technische Universität Wien in 2006, the MSc in computational mathematics from Brunel University in 2007, and the degree of Diplomingenieur in microelectronics and in technical mathematics from the Technische Universität Wien in 2009. He completed his doctoral degree on deterministic numerical solutions of the Boltzmann transport equation in 2011. His scientific interests include generative programming of discretization schemes such as the finite element method for the use in multiphysics problems.
Simulation of Semiconductor Devices on Modern Parallel Hardware
The stagnation of clock frequencies and the resulting increase of the number of cores in modern processors imposes new challenges for semiconductor device simulation: Existing algorithms have to be parallelized or even replaced with new algorithms which are better suited for multiple processing cores. If such a parallelization is not applied, the use of newer hardware for semiconductor device simulation will not provide any substantial benefits over older hardware. In order to make our simulators run efficiently on current and future hardware generations, we conducted research and code development for multi- and many-core computing architectures.
The computational hot spot of classical and semi-classical device simulation usually is the solution of systems of linear equations obtained from linearizations within a Newton method for the full nonlinear system. We focused on a full parallelization of iterative solvers for such systems of linear equations on multi-core Central Processing Units (CPUs) as well as Graphics Processing Units (GPUs) with hundreds to thousands of concurrently executed threads. Our investigations revealed that solver execution times for typical system sizes used in semiconductor device simulations can be improved by avoiding unnecessary data transfers across the memory bus (CPUs and GPUs) and by reducing latency effects via a smaller number of compute kernels launched on GPUs. These approaches are now implemented and freely available to the public in our free open-source solver library ViennaCL. A comparison of solver execution times in Fig. 1 for different system sizes shows that our approach for GPUs is by up to a factor of three faster than other publicly available GPU solver libraries. In this benchmark we considered the solution of the equations for linear elasticity using a finite element discretization, which is a common setting for the investigation of electromigration in interconnects and computationally comparable to a solution of the drift-diffusion system for semiconductors.
Our current research aims to not only reduce the amount of time required for each iterative solver iteration, but also to reduce the total number of solver iterations required for convergence. This is commonly achieved through so-called preconditioners, which are notoriously hard to parallelize, especially for GPUs. With all these improvements in place, we expect to have the most efficient classical and semi-classical semiconductor device simulators worldwide, which will strengthen the reputation of the Institute for Microelectronics as one of the leading research institutions in the field.
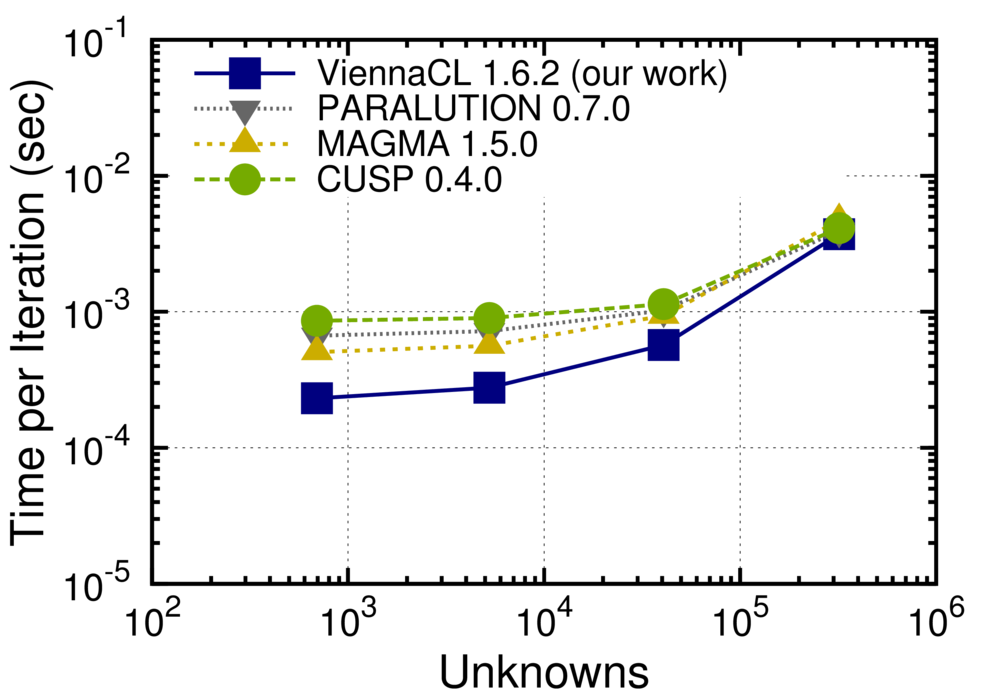
Fig. 1: Comparison of execution times for a generalized minimum residual solver applied to the solution of the linear elasticity equations with a tetrahedral mesh. Our improved implementations in ViennaCL provide up to three-fold performance gains over implementations in the freely available packages CUSP, MAGMA, and PARALUTION. The highest gains are obtained for system sizes below 10,000 unknowns, where latency effects dominate.
