
 |
|
Biography
Josef Weinbub holds a bacherlor's degree in electrical engineering, a master's degree in microelectronics, and a doctoral degree in technical sciences from the Technische Universität Wien. He was a visiting researcher at EPCC, University of Edinburgh and the Device Modelling Group, University of Glasgow, Scotland, UK. He leads the Christian Doppler Laboratory for High Performance TCAD, where he and his team investigate cutting-edge research problems in the area of high performance process TCAD. In general, however, he conducts research in the field of computational science, with a special focus on software engineering, algorithms, data structures, software frameworks, visualization, and high performance computing.
Parallelization of the Fast Marching Method Using an Overlapping Domain-Decomposition Approach
Simulating an expanding front is a fundamental step in many computational science and engineering applications, such as image segmentation, brain connectivity mapping, medical tomography, seismic wave propagation, geological folds, semiconductor process simulation, and computational geometry. In general, an expanding front originating from a start position is described by its first time of arrival to the points of a domain. This problem can be described by solving the Eikonal equation. The most widely used method for solving this equation is the fast marching method (FMM). The FMM solves the Eikonal equation in a single pass, allowing one to track the evolution of an expanding front. This method is inherently sequential, and attempts to parallelize it have so far been unsatisfactory.
Although methods that inherently favor parallelism are available, such as the fast iterative method (FIM), the FMM, as a one-pass algorithm (i.e. non-iterative in nature), offers significant advantages with respect to accuracy. For this reason, the original serial FMM remains the predominantly used method to compute expanding fronts, even now in the age of parallel computing. In particular, FMM boasts two major advantages over other techniques, (1) the narrow band formulation and (2) the monotonically increasing order of the solution, both of which represent the primary motivation for attempting to parallelize the FMM.
A parallel FMM has been developed to utilize modern multi-core architectures. Investigations focus on three-dimensional Cartesian grids and use an overlapping domain decomposition technique for parallelizing the FMM, which fits the performance-critical data locality aspects paramount to modern shared-memory environments. A shared-memory implementation based on OpenMP has been investigated and compared with a reference FIM implementation. Fig. 1. compares the parallel speedup of a two-socket (16 physical/32 logical cores) Intel Xeon compute node. Speedup of up to 100% is achieved when using 16 threads. A tendency for super-linear scaling, due to the decomposition scheme, can be identified. For one thread, the required additional decomposition logic results in a disproportionate increase in overhead that is alleviated for higher thread numbers. For more than eight threads, however, the bookkeeping required for handling larger thread numbers once again counters this effect.
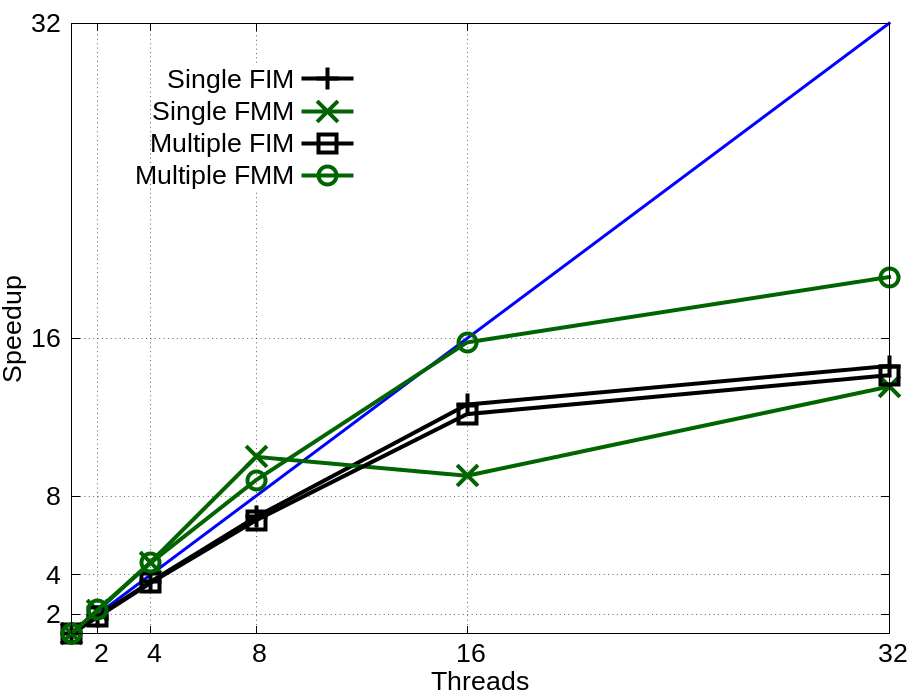
Fig. 1: Speedup of the parallel fast marching method (green) in comparison to a reference fast iterative method implementation (black) using a computationally demanding speed function. Performance for single and multiple input sources, describing the initial front, are compared on a 2003 Cartesian grid.
