
 |
|
Biography
Georgios Diamantopoulos was born in Athens,Greece in 1988. He holds a degree in applied mathematics from the University of Crete, Greece and a Master's degree in computational engineering from the Friedrich-Alexander University of Erlangen-Nuremberg, Germany. He joined the Institute for Microelectronics on January 2016 as a research assistant. He is researching high performance numerical approaches for Technology CAD within the scope of the Christian Doppler Laboratory for High Performance TCAD.
A Shared-Memory Parallel Multi-Mesh Fast Marching Method for Re-Distancing Problems
The fast marching method (FMM) is a widely used method for the solution of the Eikonal equation. Among its potential applications is the restoration of the signed distance field property by calculating the distances between discrete grid points and an interface. Recently, a promising approach based on overlapping domain decomposition has been introduced, offering the attractive parallelization of an otherwise serial algorithm. We developed an extension of this work by introducing a multi-mesh FMM that processes an arbitrary number of meshes with the same resolution, potentially sharing interfaces, in parallel. Such a scenario arises, for instance, in adaptive mesh refinement approaches, where several meshes with a certain resolution are defined based on specific regions of interest. The approach uses OpenMP tasks to apply a serial FMM algorithm in parallel to individual meshes, supporting load-balancing and interface-sharing meshes via synchronized data exchange. The parallel performance is examined on a dual-socket Ivy Bridge-EP compute node.
Fig. 1 shows a test case where meshes are defined around the quad-holes structures on the interface. On the left side (a), 48 meshes of various sizes are defined with a resolution of 0.005, and on the right side (b), 303 meshes with a resolution of 0.00125. The parallel speed-up of the algorithm for this test case is visualized in Fig. 2. As can be seen in both cases, the performance for up to 8 threads is scalable - efficiency is around 88%. In the case of 48 meshes, the speed-up drops off beyond 8 threads. The reason for this performance drop is that there are 8 meshes for which the FMM requires a runtime at least 10 times higher than all other meshes, which causes a massive load imbalance. In the case of 303 meshes, performance is scalable - efficiency is around 75% or more - even for up to 16 threads.
Our approach offers good speed-up in cases where the number of meshes is significantly larger than the available compute cores, favoring the approach's inherent load-balancing capabilities.
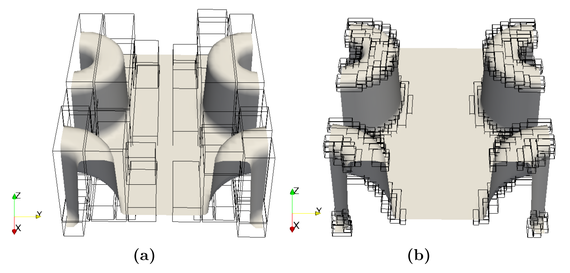
Fig. 1: Quad-holes test case: (a) 48 meshes and (b) 303 meshes.
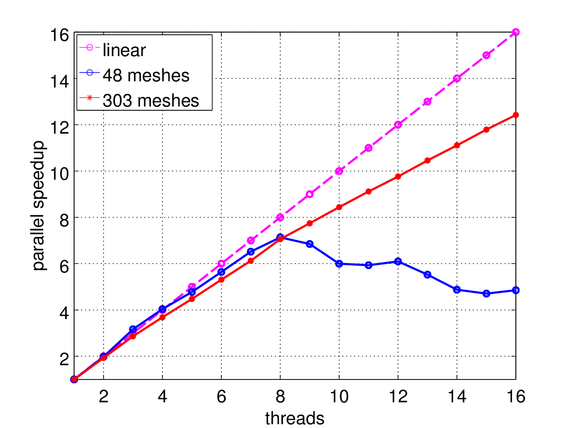
Fig. 2: Parallel speed-up for the quad-holes test case with 48 and 303 meshes (cf. Fig. 1).
