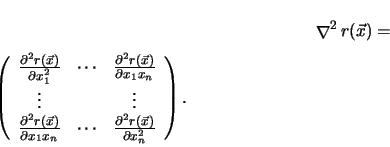 |
(4.19) |
The use of a finite-difference approximation of the first derivatives is not suitable for this purpose. They would need a very large amount of function evaluations.
A good approximation of the curvature of the nonlinear function without additional function evaluations can be computed by an iterative scheme, where the gradient of the current and last step and the Hessian of the last step are used.
In the Broyden-Fletcher-Goldfarb-Shanno [63] (BFGS) update the approximative Hessian
matrix
![]() 4.2 is calculated from the approximation of the last step
4.2 is calculated from the approximation of the last step
![]() with:
with:
In (4.20)
the vectors
![]() denote the last step and
denote the last step and
![]() the difference of the gradient vectors. The
direction of search is assumed to be the Newton direction
(see 4.1.4).
the difference of the gradient vectors. The
direction of search is assumed to be the Newton direction
(see 4.1.4).
The algorithm starts with the identity matrix as an initial value of the approximated Hessian matrix. Hence the first iteration of the Newton step is equivalent to an iteration of a steepest-descent method.
Other iterative update formulas are the Powell-Symmetric-Broyden (PSB)
 |
(4.23) |


